🦆 Welcome to QuackChat: The DuckTypers' Daily AI Update!
Hello, DuckTypers! Prof. Rod here, ready to dive into the exciting world of AI. Today, we're exploring some fascinating developments that are reshaping how we approach creativity and technical problem-solving. So, grab your favorite rubber duck, and let's decode these innovations together!
🎵 AI Composing Symphonies: The Future of Music Creation
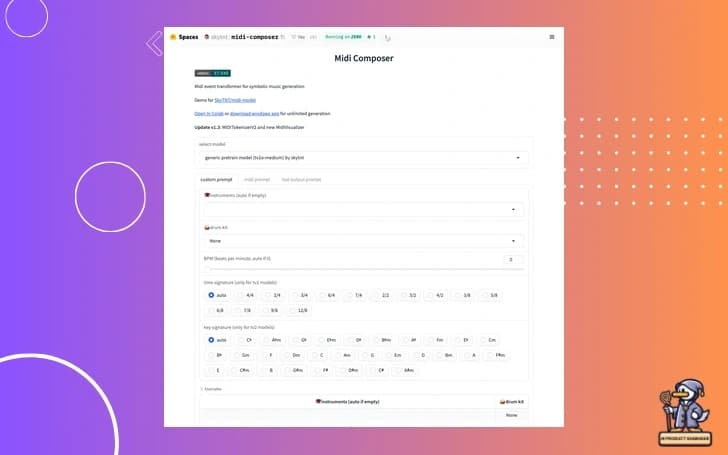
Let's kick things off with a topic that's music to my ears - literally! We've got a new player in town when it comes to AI-powered music composition.
A member of our community shared a link to a complete music composer built on HuggingFace Spaces using Gradio. Now, this isn't just another MIDI generator. It uses a MIDI event transformer model for music generation.
Here's a simple pseudocode to illustrate how such a system might work:
def compose_music(style, length, instruments):
melody = generate_melody(style, length)
harmony = create_harmony(melody, style)
arrangement = arrange_music(melody, harmony, instruments)
return create_midi(arrangement)
def generate_melody(style, length):
# AI magic happens here
pass
def create_harmony(melody, style):
# More AI wizardry
pass
def arrange_music(melody, harmony, instruments):
# AI orchestration
pass
def create_midi(arrangement):
# Convert to MIDI format
pass
This is a simplified version, of course. The actual implementation would involve complex neural networks trained on vast amounts of musical data.
Question for you, DuckTypers: How do you think AI-generated music might impact the music industry? Could we see AI composers collaborating with human musicians in the future? Share your thoughts in the comments!
🎥 Lights, Camera, AI Action: Video Understanding Models
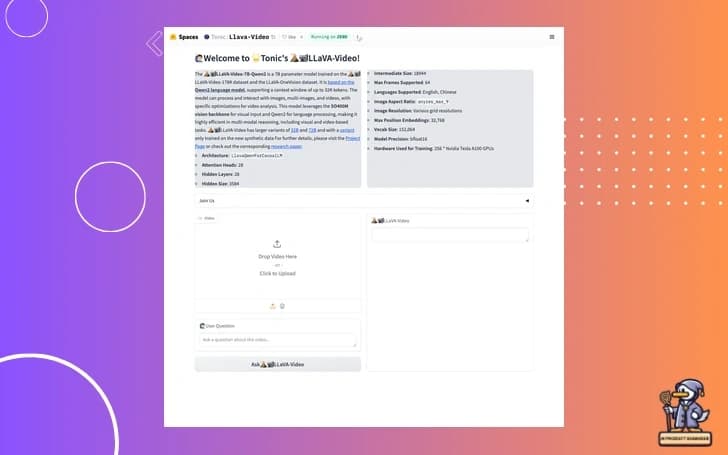
Now, let's shift our focus from audio to video. We've got an update in the world of video understanding models. A fresh demo of the Llava Video Understanding Model has been released, showcasing its capabilities in video comprehension.
This is a step forward in computer vision and natural language processing. Imagine an AI that can watch a video and describe what's happening, answer questions about the content, or even predict what might happen next.
Here's a simplified representation of how such a model might process a video:
def analyze_video(video_file):
frames = extract_frames(video_file)
objects = detect_objects(frames)
actions = recognize_actions(frames)
context = understand_context(objects, actions)
return generate_description(context)
def extract_frames(video_file):
# Extract key frames from the video
pass
def detect_objects(frames):
# Identify objects in each frame
pass
def recognize_actions(frames):
# Identify actions occurring across frames
pass
def understand_context(objects, actions):
# Interpret the overall context of the video
pass
def generate_description(context):
# Generate a natural language description
pass
This model could have applications ranging from improving accessibility for visually impaired individuals to enhancing content moderation on video platforms.
Here's a challenge for you, DuckTypers: How would you use a video understanding model in your projects? Could it be integrated into existing applications to add new features? Share your innovative ideas!
🚀 Optimizing the Brain: Advancements in Model Efficiency
Let's switch gears and talk about something that's crucial for all of us working with AI models - optimization. We've got some developments in this area.
First up, we have the introduction of minGRUs, a simpler form of Gated Recurrent Units (GRUs) that eliminates hidden state dependencies. This isn't just a minor tweak - we're talking about a potential 175x boost in training speed!
Here's a simplified comparison of a traditional GRU and a minGRU:
# Traditional GRU
def gru_cell(input, hidden_state):
update_gate = sigmoid(W_z * input + U_z * hidden_state)
reset_gate = sigmoid(W_r * input + U_r * hidden_state)
new_memory = tanh(W * input + U * (reset_gate * hidden_state))
hidden_state = update_gate * hidden_state + (1 - update_gate) * new_memory
return hidden_state
# minGRU
def min_gru_cell(input):
update_gate = sigmoid(W_z * input)
new_memory = tanh(W * input)
output = update_gate * input + (1 - update_gate) * new_memory
return output
As you can see, the minGRU simplifies the computation by removing the dependency on the previous hidden state. This not only speeds up training but also allows for better parallelization.
But that's not all, folks! We've also got news about a new library from PyTorch called torchao. This library introduces advanced techniques like quantization and low-bit datatypes, optimizing models for performance and memory efficiency.
Here's a quick example of how you might use torchao for quantization:
import torch
import torchao
# Define your model
model = MyNeuralNetwork()
# Quantize the model
quantized_model = torchao.quantize(model, dtype=torch.qint8)
# Now you can use the quantized model for inference
output = quantized_model(input_data)
This simple operation can significantly reduce the memory footprint of your model and speed up inference, especially on hardware with dedicated support for quantized operations.
Question for the DuckTypers: How might these optimization techniques change your approach to model design and deployment? Could they enable new applications that weren't feasible before? Share your thoughts!
💡 AI in Action: From Text to Tunes
Now, let's talk about an intriguing request from our community that bridges our earlier topics of music and natural language processing. A member expressed their ongoing search for a text to singing model or methodology.
This is a fascinating challenge that combines several areas of AI:
- Natural Language Processing (NLP) to understand the text
- Music Generation to create a melody
- Voice Synthesis to produce the singing voice
Here's a high-level pseudocode of how such a system might work:
def text_to_singing(lyrics):
phonemes = text_to_phonemes(lyrics)
melody = generate_melody(phonemes)
rhythm = align_rhythm(phonemes, melody)
voice_params = extract_voice_parameters(phonemes)
audio = synthesize_voice(phonemes, melody, rhythm, voice_params)
return audio
def text_to_phonemes(lyrics):
# Convert text to phonetic representation
pass
def generate_melody(phonemes):
# Create a melody that fits the phonemes
pass
def align_rhythm(phonemes, melody):
# Adjust the rhythm to fit the phonemes and melody
pass
def extract_voice_parameters(phonemes):
# Determine parameters like pitch, timbre, etc.
pass
def synthesize_voice(phonemes, melody, rhythm, voice_params):
# Generate the final audio of the singing voice
pass
This is a complex problem that pushes the boundaries of current AI technology. It requires not just understanding of language and music, but also the nuances of how humans sing.
Here's a challenge for you, DuckTypers: How would you approach building a text-to-singing model? What datasets would you need? What challenges do you foresee? Share your ideas in the comments!
🎓 Wrapping Up: The AI Symphony Continues
Well, DuckTypers, we've covered a lot of ground today. From AI composing music to understanding videos, from optimizing our models to potentially creating singing voices from text. These advancements show just how diverse and exciting the field of AI is becoming.
As we wrap up, I want you to think about how these developments might impact your work or your everyday life. Are we moving towards a future where AI becomes a creative partner rather than just a tool? How might these optimizations change the way we deploy AI in resource-constrained environments?
Let's learn from each other and grow together as a community of AI enthusiasts and developers.
Until next time, keep questioning, keep innovating, and most importantly, keep your rubber ducks close at hand. This is Prof. Rod, signing off from QuackChat: The DuckTypers' Daily AI Update!

Written by Rod Rivera
AI Product Engineer contributor
Related Articles

Berkeley's BFCL state-based testing evaluates real system outcomes instead of just function-call syntax, making AI function-calling benchmarks closer to production reality.

Hello Ducktypers! Jens here from Munich. As a software architect, I'm particularly excited about today's developments that show how thoughtful engineering is reshaping AI...
Hello Ducktypers! Prof. Rod here, and we're diving into what I consider one of the most significant weeks in AI search history. In the last days, we've seen three developments...