🚀 Nvidia's Nemotron 70B: A New Benchmark in AI Performance
Hello, Ducktypers! Jens here. Today, we're examining Nvidia's Nemotron 70B model, which has outperformed GPT-4 and Claude 3.5 in recent benchmarks, alongside Mistral's new edge models and advancements in model efficiency with SageAttention. These developments are sparking discussions about model evaluation methods and the democratization of AI through open-source tools.
The Unexpected Challenger: Nvidia's Nemotron 70B
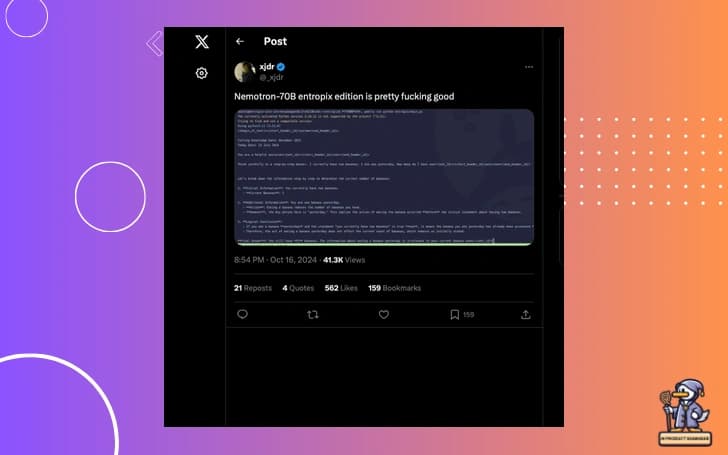
In a surprising turn of events, Nvidia has quietly released their Nemotron 70B model, and the results are turning heads across the industry. This new model isn't just keeping pace with the giants; it's surpassing them.
According to recent benchmarks, Nemotron 70B has outperformed both GPT-4o and Claude 3.5 Sonnet on several key evaluations. For instance, on the Arena Hard benchmark, Nemotron 70B scored an impressive 85.0, compared to 79.2 and 79.3 for its competitors.
Now, as an engineer, I'm always cautious about extraordinary claims. Let's break this down a bit:
def compare_model_performance(model_scores):
for model, score in model_scores.items():
print(f"{model}: {score}")
best_model = max(model_scores, key=model_scores.get)
print(f"
Best performing model: {best_model}")
model_scores = {
"Nemotron 70B": 85.0,
"GPT-4o": 79.2,
"Claude 3.5 Sonnet": 79.3
}
compare_model_performance(model_scores)
This simple script helps us visualize the performance gap. But remember, a single benchmark doesn't tell the whole story. We need to consider a range of factors and real-world applications.
What are your thoughts on these results? Have you had a chance to experiment with Nemotron 70B? Share your experiences in the comments below!
Link to Nvidia's Nemotron 70B performance details
🔬 Mistral's New Edge Models: Bringing AI to Your Devices
While Nvidia is making waves in high-performance AI, Mistral is focusing on bringing powerful models to edge devices. They've just launched two new models: Ministral 3B and Ministral 8B.
These models are designed for on-device use, offering privacy-first inference capabilities and impressive context lengths of up to 128k tokens. This is a significant step towards more accessible and efficient AI applications.
Here's a quick breakdown of what makes these models stand out:
- Optimized for edge computing
- Enhanced privacy features
- Improved reasoning capabilities
- Support for longer context lengths
As someone relatively new to the AI space, I'm particularly excited about the potential applications of these edge models. Imagine the possibilities for IoT devices or mobile applications that can run sophisticated AI models locally!
Have you considered implementing edge AI in your projects? What challenges or opportunities do you foresee? Let's discuss in the comments!
More information on Mistral's new edge models
🧠 SageAttention: Revolutionizing Model Efficiency
Now, let's talk about a breakthrough that's caught my attention as a software architect. SageAttention, a new quantization method for attention mechanisms in transformer models, is showing promising results in improving inference speed and efficiency.
According to recent research, SageAttention outperforms existing methods like FlashAttention2 by 2.1 times, all while maintaining model accuracy. This is crucial for scaling AI applications and reducing computational costs.
Here's a simplified pseudocode to illustrate how SageAttention might work:
def sage_attention(query, key, value):
# Quantize inputs to 8-bit
q_quantized = quantize_8bit(query)
k_quantized = quantize_8bit(key)
v_quantized = quantize_8bit(value)
# Perform attention computation in 8-bit
attention_scores = compute_attention(q_quantized, k_quantized)
# Dequantize for final output
output = dequantize(attention_scores @ v_quantized)
return output
This approach addresses the O(N^2) complexity typically seen in attention mechanisms, potentially leading to significant performance improvements across various models.
As engineers, we're always looking for ways to optimize our systems. How do you think innovations like SageAttention could impact your AI projects? Share your thoughts!
💻 Open Tools Empowering the Community
One aspect of the AI community that continually impresses me is the collaborative spirit and the development of open tools. Let's look at a few recent developments:
-
Open Interpreter + Ollama: This integration now allows running any GGUF model on Hugging Face via Ollama, making local LLMs more accessible. Here's a simple command to get you started:
ollama run huggingface.co/username/repository -
Inferencemax: A new project aimed at simplifying LLM inference. While still in development, it shows promise in making AI more accessible to developers.
-
AIFoundry.org: This initiative is seeking guidance to improve their GitHub organization, aiming to enhance their open-source local model inference projects.
These tools are lowering the barriers to entry in AI development. As someone who values simplicity in engineering, I'm excited to see how these projects evolve.
Have you used any of these tools in your work? What has been your experience? Let's share some insights!
Explore Open Interpreter and Ollama
🔍 The Ongoing Debate: Model Evaluation and Benchmarks
As we wrap up, I want to touch on an important topic that's been buzzing in the AI community: the reliability and interpretation of model benchmarks.
The impressive performance of Nvidia's Nemotron 70B has reignited discussions about how we evaluate and compare AI models. Some key points to consider:
- Benchmark diversity: Are we using a wide enough range of tests?
- Real-world applicability: How do benchmark results translate to practical use cases?
- Reproducibility: Can results be consistently replicated across different environments?
As engineers, we know the importance of thorough testing and validation. It's crucial that we approach these benchmarks with a critical eye and consider multiple factors when evaluating model performance.
What are your thoughts on the current state of AI model evaluation? Do you think we need new or improved benchmarking methods? Share your perspectives in the comments!
That's all for today's QuackChat AI Update, Ducktypers! In this QuackChat AI Update, we covered Nvidia's Nemotron 70B model outperforming its competitors, Mistral's new edge models for on-device AI, the efficiency gains of SageAttention, the growth of open-source AI tools, and the ongoing debate about AI model evaluation methods and benchmarks.
Until next time, keep coding, keep questioning, and keep pushing the boundaries of what's possible with AI!

Written by Jens Weber
AI Product Engineer contributor
Related Articles

Berkeley's BFCL state-based testing evaluates real system outcomes instead of just function-call syntax, making AI function-calling benchmarks closer to production reality.

Hello Ducktypers! Jens here from Munich. As a software architect, I'm particularly excited about today's developments that show how thoughtful engineering is reshaping AI...
Hello Ducktypers! Prof. Rod here, and we're diving into what I consider one of the most significant weeks in AI search history. In the last days, we've seen three developments...